Transformer 模型笔记
现在手头上接触的很多线上功能都使用了 transformer 这种深度学习的模型(手头上的 ASR 和 TTS 都不约而同的用了),虽然我只做工程的实现(对我就是调 API 的),但也还是想稍微深入学习一下 transformer 相关知识。
前置知识
sequence to sequence 模型
其实这个比较好解释,指的是模型的输入是一个序列信息(可以是文本,音频,视频etc),输出也是序列信息。典型的如翻译模型,从中文翻译到英文。
一般地,Sequence to sequence 模型会由一个 encoder 和 decoder 组成。他们都是 RNN (或者类似结构的)模型。处理模式大致为:输入 -> encoder -> context(向量) -> decoder -> 输出。context 向量长度可能是 256/512/1024 等。
注意,一般而言 Sequence to sequence 的模型的 encoder 在运行时会维护一个 hidden state 的信息,但这个信息不会直接传递给 decoder。实际上输出信息给到 encoder 之后,需要等待 encoder 的 RNN 网络处理完得到 context, 再把 context 传递给 decoder。
Attention 机制
在很多地方都提到了《Attention is all you need》这一篇文章,算是最初的源头。Attention的思想理解起来比较容易,就是在 decoding 阶段对input中的信息赋予不同权重。在nlp中就是针对 sequence 的每个time step input,在cv中就是针对每个pixel。
思想简单,具体到实现上就有点麻烦了。我看了很多参考资料(大部分中文资料都是互相抄一抄),然而还是云里雾里。
简单而言,Attention 就是我们把 encoder 中的每一次 hidden state 都传给 decoder,同时 decoder 根据当前的输入位置去对 hidden state 进行加权平均的到当前注意信息,连同 context 一并输入。
Transformer
Attention 机制帮助提升了机器翻译的质量,transformer 模型则让模型训练可以并行化,大大提升训练效率。我们以翻译为例子说明 transformer 模型。
典型的 sequence to sequence 如下图
在文献中 encoders 是由6个子网络层叠而来。每个网络的结构是一样的(当然它们的权值并不共享)。decoder 同理。注意到 encoder 的网络的最后一次输出(其实是下文中出现的 K 和 V )输入到每一层 decoder 中。
对于一个 encoder 的子网络,它由 self-attention 和 feed forward 两层组成;对于一个 decoder 的子网络,它由 self-attention,encoder-decoder attention,feed forward 三层组成
- self-attention:当前翻译和已经翻译的前文之间的关系
- encoder-decoder attention:当前翻译和编码的特征向量之间的关系
对于 encoder 的输入,它其实是结果 embedding algorithm 得到的词向量(实际上是把词映射成一个高维向量,注意这里并不是简单的 index,这里具体不展开了)。词向量的长度会取大于我们需要翻译句子的最大长度的2的幂(不是很理解为什么?)。
self-attention
Self-attention 指的是句子中的某个词和其他部分的相关程度。比如下面这句话
The animal didn't cross the street because it was too tired
句子中的 it 明显指代 animal,但对于机器来说,这就比较困难了:it 是指代 animal 还是 street?Self-attention 就是解决这个问题的方法——计算 it 和句子中其他词的相关度。
步骤一
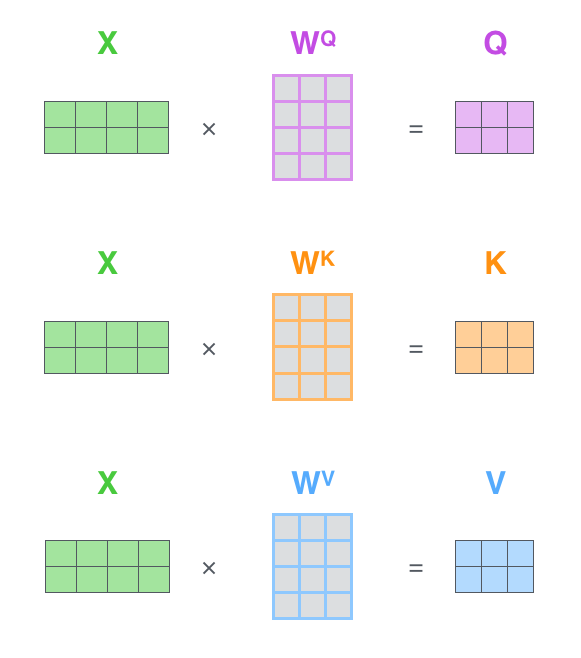
从 encoder 的每一个输入(即一个个 embedding 后的词向量)构造 3 个向量,文献中称之为 Query/Key/Value vector。这三个向量实际上是将词向量和 \(W^Q\),\(W^K\),\(W^V\) 矩阵相乘得到的(这3个矩阵是训练过程中训练得到的,不过这个是怎么训练的呢?)。注意到 Query/Key/Value vector 的维度是一致的,但是不一定需要和词向量的维度一致。一般来说为了计算效率,Query/Key/Value vector 的维度会低于词向量的维度,比如词向量512维,QKV 64维。
步骤二
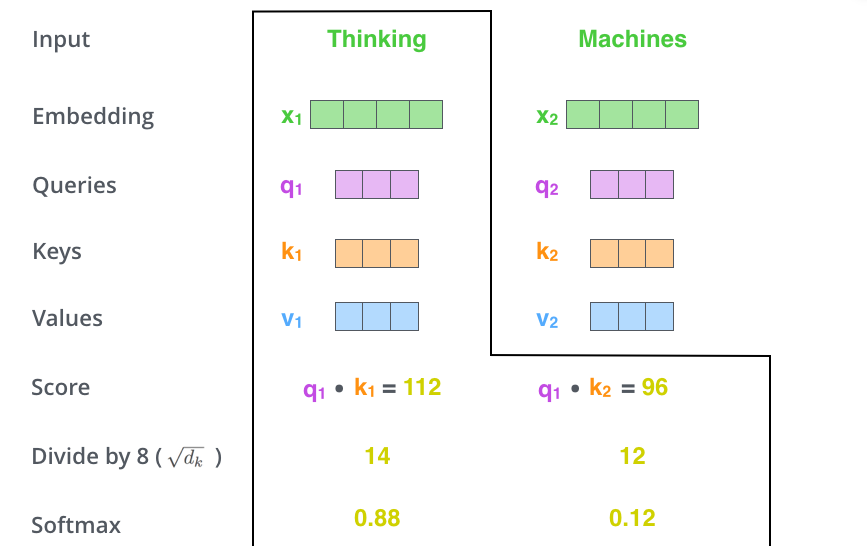
计算单个词(词向量)相对于整个句子的 score。比如第一个词 Thinking,它在位置 1 的分数是 \(q_1 \cdot k_1\),位置 2 的分数是 \(q_1 \cdot k_2\),以此类推。
步骤三
对计算得到的分数除以 8,即 QKV 维度的开平方 \(\sqrt{64}=8\),据说是为了有更好的梯度,我感觉更像是拍脑瓜想出来的注意。然后再对这些 score 进行 softmax。
步骤四
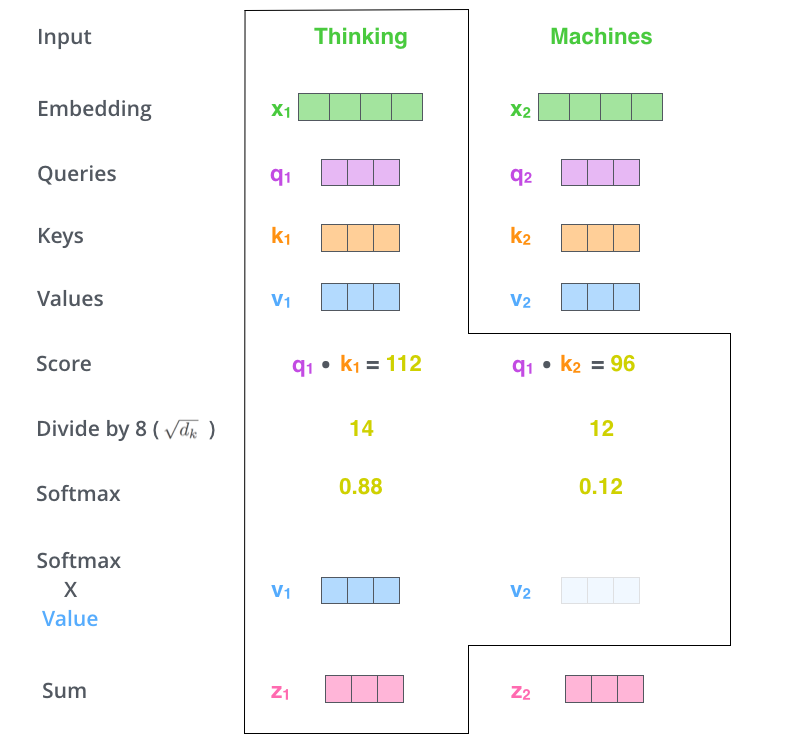
现在要用到 Value 向量了。处理也很简单,就是将上面计算得到的 softmax 乘上 value 向量,再统统累加在一起,得到最终的该词的 self-attention 值。即 \(z_1 = v_1softmax_1+v_2softmax_2\)。注意这里的 \(z_2\) 指代的是第一个词 Thinking 在第二个位置的 self-attention 值。
矩阵化操作
在最开头我们提到过 Transformer 模型可以很好地并行化,实际上是用矩阵乘法得到。上述 self-attention 矩阵化计算如下。\(X\) 的每一行都是代表一句话中的一个词向量
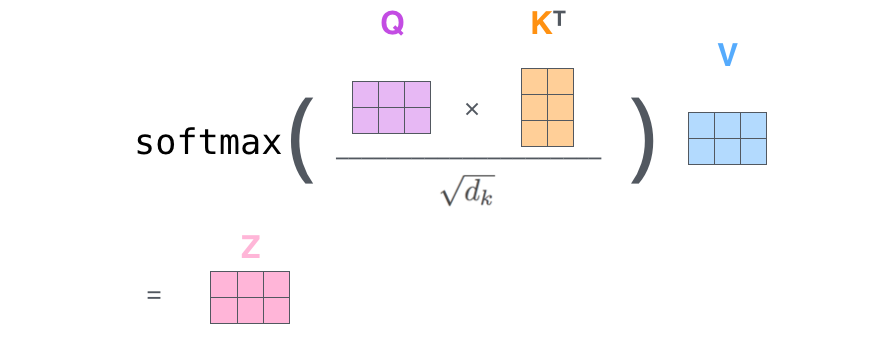
multi-headed attention
文章中扩展了 self-attention 的概念为 multi-headed attention
- 它扩展了模型专注在不同位置能力。在上面的 self-attention 例子中,\(z_1\) 几乎不包含其他位置的词的信息(实际上只有 \(k\) ),所以可以认为 \(z_1\) 受到词本身的影响很大。(我其实没太理解这一点)
- 它赋予了注意力层多个表达子空间。这个很明显,实际上它用了多组 QKV,自然表征空间更大。
multi-headed attention 比较简单,就是把 self-attention 拷贝8份(当然权值不一样),然后把每个 head 得到的 self-attention 连接起来,最后将这个连起来的向量乘以一个训练好的矩阵 \(W^O\),得到的结果我们称它为 \(Z\) 。
然后还是看回 The animal didn't cross the street because it was too tired 这句话。里面的两个 head 的 self-attention 在 it 的位置如下。这里有个小问题,每一个 head 的 self-attention 应该是一个向量,但图中直接用了一个色块表示,是直接取向量的模?
位置编码
在输入端光是有词向量(word embeddings)是不够的,我们还需要每一次输入的位置信息。一个简单的方法是在输入的向量前增加位置编码向量。
位置编码向量有很多种,文献中用的是三角函数生成。用三角函数的好处在于理论上它可以在有限的维度中表示任意长度句子的相对位置。实际上,只要位置编码可以表示词在句子中的相对位置就可以,并不一定需要使用三角函数。
残差连接
Transformer 的网络里还有个小细节需要注意,在每一个子层里(包括 self-attention,feed forward)都有一个残差连接(主要是为了解决梯度爆炸/梯度消散问题)。如下图就是 encoder 里的残差连接。
Decoder 网络
Encoder 从输入一个序列开始,encoder 的最终输出是一系列的 attention vector K 和 V
Decoder 的 self-attention 层和 encoder 的有些许不同。decoder 的 self-attention 层只允许关联之前的位置(通过在 softmax 之前增加一个 -inf 的 mask 实现)。Decoder 中的 Encoder-decoder attention 层的计算方式和 self-attention 类似,但是它的 Queries 矩阵来自于它的前一层,而 Keys 和 Values 矩阵则来自于 encoder 的输出。
最后,在 decoder 网络的后面挂一个 softmax 就可以得到最终的词结果。
参考文献
https://zhuanlan.zhihu.com/p/47063917